Dans le cadre de la semaine internationale du libre accès, la journée d’études organisée à Lyon le 25 octobre a eu pour thème Pour une science ouverte et éthique. Le programme est disponible ici et les enregistrements vidéo des conférences du matin là. L’après-midi, un des ateliers, animé par Marilou Pain (CCSD), était consacré à la diffusion des données de recherche.
Ce billet propose une partie du contenu de la présentation.
Quelques éléments de contexte
On assiste aujourd’hui à un phénomène de parcellisation de l’article scientifique. De plus en plus concis, il se sépare peu à peu des protocoles, des aspects méthodologiques ainsi que de des données de recherche. Ce phénomène se trouve encouragé par les recommandations, injonctions et parfois obligations formulées à la fois par les institutions de recherche, les organismes de financement ainsi que les éditeurs.
On peut définir les données de recherche comme des entités collectées, observées ou créées à des fins d’analyse pour établir des résultats scientifiques (Borgman 2015, Livre Blanc CNRS 2016). Cette définition englobe une diversité d’objets difficilement mesurable. Chaque discipline, chaque communauté scientifique et peut-être même chaque chercheur établira une définition différente des données de la recherche, en fonction de sa culture disciplinaire ou de ses objets de recherche.
Les données de la recherche peuvent être catégorisées selon leur nature, en prenant comme axe d’analyse les objets étudiés lors de la recherche les ayant produites, ainsi que selon les méthodes d’obtention mises en œuvre.
Les données peuvent ainsi être dites d’observation. Elles sont alors soit descriptives, c’est-à-dire uniques et collectées par des individus ou des machines, ou bien expérimentales, c’est-à-dire récoltées en changeant les conditions de réalisation d’un phénomène pour en étudier les étapes. D’autre part, on trouve des données dites traitées ou dérivées qui se composent de données retravaillées pour une meilleure compréhension ou une normalisation, ou bien des données de simulation issues de combinaison de modèles mathématiques ou informatiques.
Enfin, on peut également catégoriser les données de recherche selon l’étape atteinte dans leur cycle de vie, comme c’est le cas pour les données dites traitées. On distinguera alors les données brutes, entendues comme des données qui viennent d’être créées, neutres et objectives et ne dépendant pas de leur contexte de création, d’une analyse ou de leur producteur (Thessen 2011), des données traitées et analysées, c’est-à-dire ayant subi des opérations de nettoyage, de sélection et d’analyse afin de produire des résultats. Néanmoins, ces frontières semblent floues et varient, encore une fois, selon l’approche disciplinaire. Certains remettent ainsi en question la notion de données brutes, arguant que la méthodologie de création ou encore le rejet de certaines « mauvaises données » mettent déjà en œuvre un processus de traitement et ainsi une forme de subjectivité.
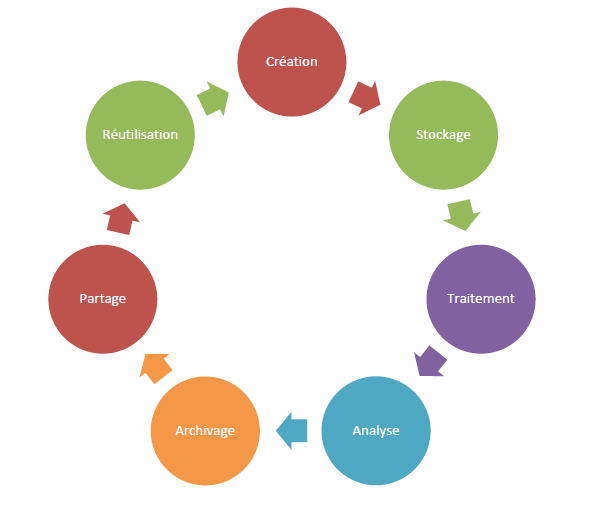
Cycle de vie des données de la recherche
Lors de cet atelier, nous nous sommes intéressés tout particulièrement aux étapes d’archivage et de partage des données de recherche, en gardant à l’esprit les objectifs de préservation, de diffusion ainsi que de validation et de réutilisation des données inhérents à ces étapes.
Le partage des données est présenté comme un des éléments clés de la science ouverte dans le livre blanc du CNRS. Or, cette thématique mobilise des enjeux forts auprès des divers acteurs de la recherche scientifique, acteurs qui ont parfois des intérêts contradictoires. Ainsi, les chercheurs, en tant que créateurs, sont des acteurs centraux pour qui la diffusion des données permettra aux auteurs d’être crédités et aux autres chercheurs de citer et réutiliser ces données. Il semble essentiel que les chercheurs soient au centre du processus de partage, en tant que personnes les plus à même de décrire d’un point de vue disciplinaire les données, d’autant plus que certains émettent des réserves vis-à-vis du partage des données comme l’a évoqué C. Boukacem lors de son intervention du matin.
Les acteurs institutionnels quant à eux, pourront promouvoir des recommandations et des standards afin que les métadonnées s’inscrivent dans un environnement connecté, valorisant ainsi les activités de recherche se déroulant en leur sein.
Enfin, de forts enjeux socio-économiques gravitent autour des données de la recherche et de leur partage. Tout d’abord, cette diffusion peut être vue comme une forme de retour à la société, de même, les sciences citoyennes aujourd’hui en essor pourraient bénéficier de ce phénomène. Néanmoins, les questionnements éthiques, notamment d’anonymisation et d’impacts sociétaux de la recherche restent présents et ont été largement décrits par l’intervention de S. Carvallo. De plus, les éditeurs ainsi que les nouveaux acteurs économiques s’emparent de ce sujet en proposant des services et infrastructures basés sur les données de recherche, ce qui met en exergue la valeur économique potentielle de celles-ci.
Où diffuser mes données de recherche ?
Les données de recherche peuvent être diffusées aussi bien sous la forme d’un fichier unique que d’un jeu de données (data set, data package ou file set). Nous avons abordé ici uniquement les données numériques.
Concernant le lieu de diffusion, plusieurs solutions existent et ne sont pas forcément incompatibles entre elles :
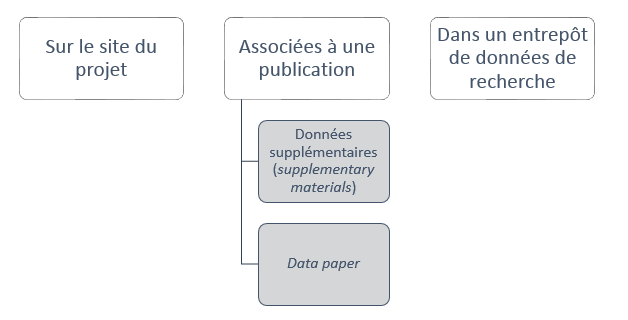
La simple diffusion sur le site du projet ne garantit pas que ces données puissent aisément être retrouvées, ni archivées. Les deux autres solutions offrant a priori des liens pérennes vers le jeu de données, il semble plus pertinent de s’orienter vers celles-ci. Les données supplémentaires constituent la forme classique de présentation des données de recherche, accolées à la publication.
Néanmoins, les éditeurs semblent petit à petit se séparer de ce format où les données sont la plupart du temps présentées sous un format non réutilisable pour s’orienter vers les data paper. Ces publications parfois rassemblées au sein de data journals sont constituées du jeu de données et peuvent être liées à la publication d’origine.
Enfin, une dernière forme de diffusion potentielle des données de recherche est constituée des entrepôts de données. Une infrastructure dédiée, créée pour les données de recherche et offrant des services d’archivage, de diffusion ou d’éditorialisation des données plus ou moins étendus. Ces entrepôts sont, à l’image des données qu’ils recueillent, multiples. Ils peuvent être :
- consacrés à un projet unique,
- disciplinaires,
- institutionnels,
- généralistes,
- interdisciplinaires.
Durant la troisième partie de l’atelier, nous avons abordé le fonctionnement de quelques entrepôts généralistes ou interdisciplinaires tels que HAL, Nakala, Dryad, Zenodo ou Figshare, en s’interrogeant sur certains de ces critères.
Par exemple, il semble important de mettre en valeur le fait que Figshare fasse partie de ces nouveaux acteurs économiques de type start-up, racheté par un groupe éditorial, ce qui nous a amené à nous questionner sur ses conditions générales d’utilisations et sur les détails de leur modèle économique.
Enfin, on a pu constater que Dryad, même modestement, propose certaines métadonnées disciplinaires qui pourraient s’avérer intéressantes en terme de recherche et de réutilisation des données ; à la différence d’entrepôts généralistes tels que Zenodo.
A la vue de l’offre actuelle, lors de la recherche d’un entrepôt de données, il semble que l’équilibrage doit aujourd’hui se faire entre des entrepôts spécialisés reconnus par une communauté disciplinaire qui offrent un cadre pertinent de description des données, et des entrepôts généralistes de taille plus conséquente, disposant d’une ergonomie plus travaillée et de services étendus.
Le second billet sera ainsi consacré à quelques outils permettant de rechercher des lieux de stockage et diffusion de jeux de données de recherche, notamment des répertoires d’entrepôts de données. De même, nous vous proposerons une liste de critères pouvant vous accompagner dans le choix d’un entrepôt.
Billet rédigé par Marilou Pain
Présentation :