Persistent identifiers (PIDs) and their associated metadata are key elements of open research infrastructures. You are familiar with DOI and ORCID, and you often hear about ROR (see blog post): they enable reliable, unique and persistent identification of researchers, institutions and resources in the research ecosystem, as well as the links between them. They support and facilitate discovery, attribution and recognition, evaluation, interoperability and more.
The PIDfest conference, held in Prague last June, brought together a large number of representatives, users and decision-makers at international level to discuss the challenges related to the support and dissemination infrastructures for scientific production, as well as the role of persistent identifiers in ensuring the accessibility, interoperability and reusability of scientific data, in line with the FAIR (Findable, Accessible, Interoperable, Reusable) principles.
The CCSD was also present: participation in this international conference was an opportunity to present the use of identifiers in HAL during a session where different use cases were presented.
Why is using persistent identifiers important?
Using HAL as an example, they allow to:
- Simplify and leverage self archiving;
- Avoid duplicates and preserve data quality and reliability;
- Make the entities discoverable and support the curation process. Build tools for research outputs monitoring;
- Track changes and enrich the metadata;
- Help moderators when verifying the compliance of the deposits.
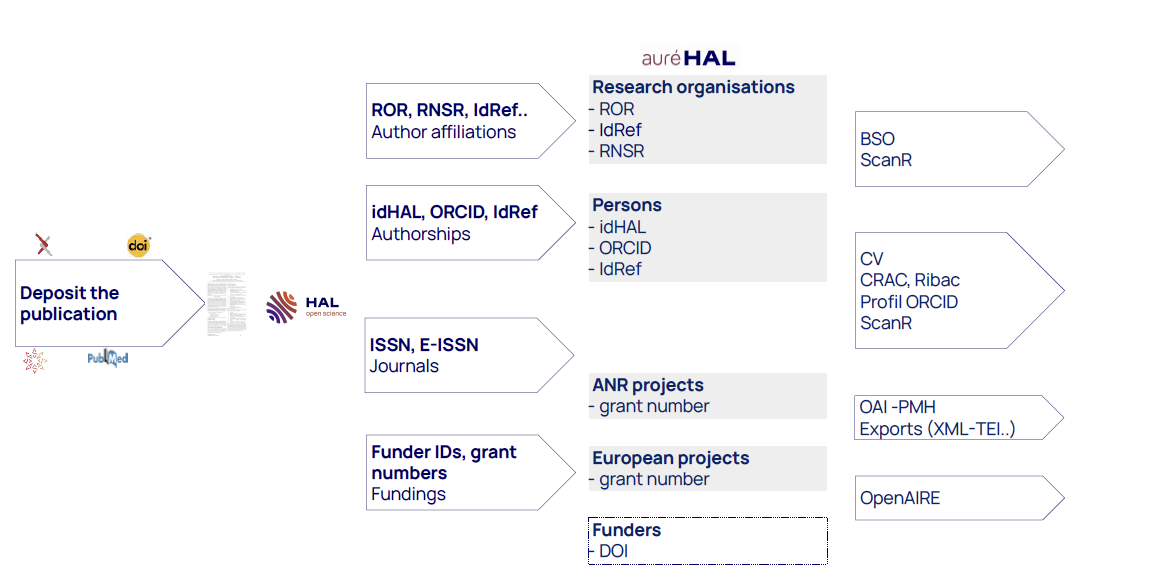
Once the deposit is recorded, several links are established between the various digital entities and the deposit. New entities can be created if they do not exist in HAL. These entities (structures, authors, journals, etc.) can be consulted, verified and validated in auréHAL by librarians or portal administrators. Improving the alignment of digital entities with real ones often involves a process of deduplication and correction, which is also carried out using auréHAL. This is central to several services and functionalities, such as CVs for authors, portals for institutions and collections based on specific criteria.
These data are accessible under the CC0 licence through various interfaces, in different formats and protocols.
This conference was an opportunity for me to discover feedback on the methods and strategies used by different organisations at the international level to raise awareness, support and guide the use of PIDs in order to meet the expectations and needs of different stakeholders. Given the diversity but also the complementarity of PID systems, this requires a good understanding of these systems and following best practices to better integrate and benefit from them. Presentations on graphs based on PIDs allowed me to understand the effectiveness of PIDs in building knowledge through links between different entities. Several other presentations on PIDs that I was not aware of, such as identifiers for samples (IGSN), resources of interest in the biomedical field (RRID), and this project to identify and assign persistent identifiers for research projects and activities (RAiD), were also enlightening.
See you at the next PIDfest!